Understanding Decision Trees: A Beginner's Guide
As a machine learning algorithm, decision trees have been widely used in various industries, from finance to healthcare to marketing. The reason why it's so popular is that decision trees can be easily understood by humans and provide a transparent way to make predictions.
Introduction to Decision Trees
Decision trees are a type of machine learning algorithm that is used for classification and regression tasks. They are a popular algorithm due to their simplicity and interpretability. Decision trees are represented in a tree-like structure, where each node represents a feature or attribute, and the edges represent the decision rules that lead to a certain outcome.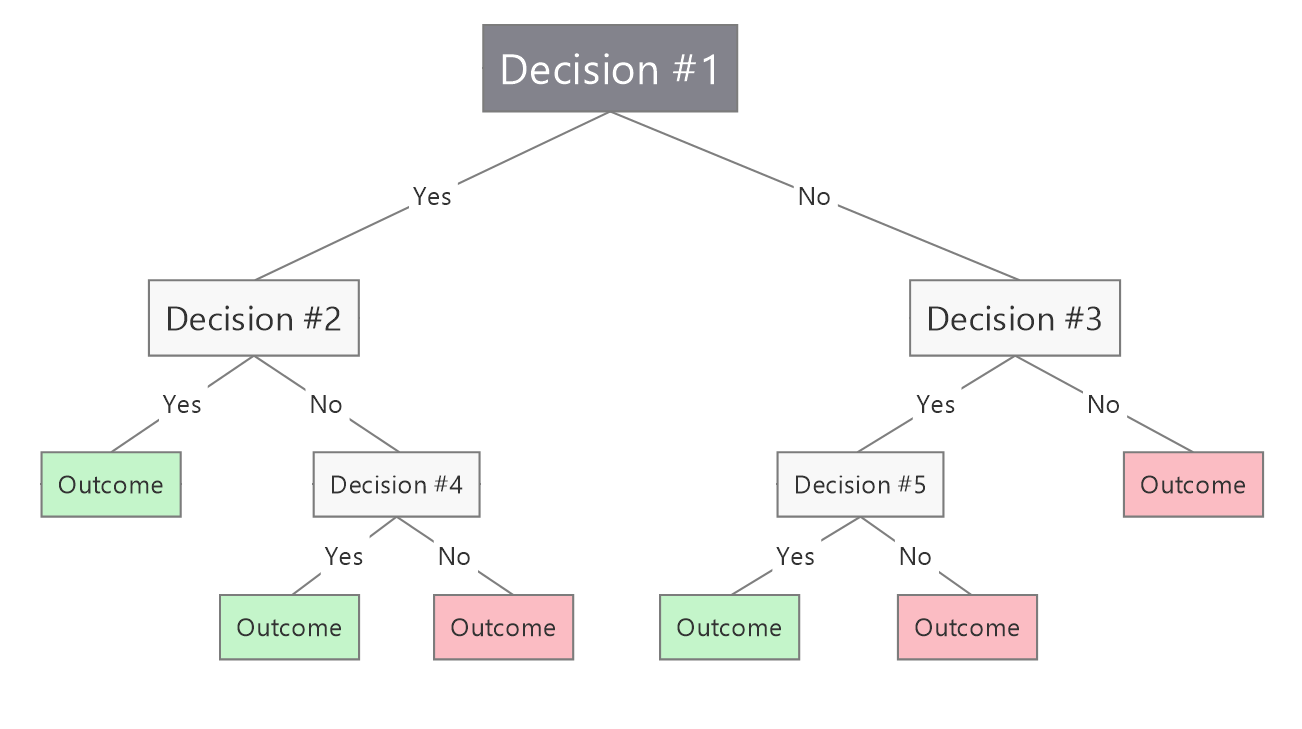
How Decision Trees Work
Decision trees work by recursively partitioning the data based on the feature that provides the most information gain. Information gain measures the difference between the impurity of the parent node and the sum of the impurities of the child nodes. The algorithm chooses the feature with the highest information gain as the split node, and the process is repeated until a stopping criterion is met, such as reaching a maximum depth or a minimum number of samples in a node.
Types of Decision Trees
Classification Trees Classification trees are used for classification problems, where the goal is to assign a label or category to an input based on its features. The decision tree algorithm partitions the data based on the feature that provides the most information gain for the classification task.
Regression Trees Regression trees are used for regression problems, where the goal is to predict a continuous output based on its features. The decision tree algorithm partitions the data based on the feature that provides the most information gain for the regression task.
Ensemble Trees Ensemble trees are a combination of multiple decision trees that work together to improve the accuracy and robustness of the model. Random Forest and Gradient Boosted Trees are popular ensemble tree algorithms.
Applications of Decision Trees
Predictive Modeling Decision trees are used for predictive modeling in various fields, such as finance, healthcare, and marketing. They can predict customer behavior, detect fraud, and diagnose diseases.
Recommender Systems Decision trees are used for building recommender systems that suggest products, movies, or music to users based on their preferences and behavior.
Natural Language Processing Decision trees are used for natural language processing tasks, such as text classification, sentiment analysis, and named entity recognition.
Assumptions :
Independence of features: Decision trees assume that the features used to split the data are independent of each other.
Linear relationships: Decision trees assume that the relationships between the features and the target variable are linear. If the relationships are non-linear, then decision trees may not be the best choice.
Homogeneity of variance: Decision trees assume that the variance of the target variable is constant across all levels of the features used to split the data.
No missing values: Decision trees require that there are no missing values in the data. If there are missing values, they need to be imputed or the observations with missing values need to be removed.
No multicollinearity: Decision trees assume that there is no multicollinearity among the features used to split the data. If there is multicollinearity, it can lead to unstable and unreliable models.
Advantages:
- Decision trees are easy to understand and interpret. They provide a clear visualization of the decision-making process, making it easy to see how decisions are being made.
- Decision trees can handle both categorical and numerical data.
- Decision trees are robust to missing data and outliers, as they can still make predictions based on the available data.
- Decision trees can help identify important features that are driving the decision-making process.
- Decision trees can be used for both classification and regression problems.
Disadvantages:
- Decision trees can be prone to overfitting, especially when dealing with complex data.
- Decision trees can be sensitive to small variations in the data, leading to different tree structures and outcomes.
- Decision trees can be biased towards features that have more levels or categories, as they are given more weight in the decision-making process.
- Decision trees can be computationally expensive to train, especially when dealing with large datasets or complex tree structures.
- Decision trees can be less accurate than other algorithms, such as neural networks or support vector machines, in certain scenarios.
- Difficulty in capturing correlations: It is often difficult for decision trees to capture correlations between different features, which can lead to poor performance in certain cases.
- Difficulty in handling continuous variables: Decision trees work best with discrete variables, and may have trouble handling continuous variables or variables with many possible values.
- Outliers: It significantly impact the performance of a decision tree. Decision trees make splits based on the information gain at each split, which is calculated using the impurity of the target variable in the split. Outliers can skew the distribution of the target variable and increase its variance, which can lead to splits that are not optimal for the majority of the data points.
Example with code :
decision tree using the Scikit-learn library in Python:
python# Import necessary libraries
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn.tree import export_text # Load iris dataset
iris = load_iris()# Split the dataset into features (X) and labels (y)
X = iris.data
y = iris.target # Initialize decision tree classifier
clf = DecisionTreeClassifier() # Train the classifier on the data
clf.fit(X, y)# Print the decision tree
tree_rules = export_text(clf, feature_names=iris['feature_names'])print(tree_rules)
This code uses the load_iris function from Scikit-learn to load the iris dataset, which consists of measurements of iris flowers along with their corresponding species. It then splits the dataset into features (X) and labels (y), initializes a decision tree classifier, trains the classifier on the data, and prints the decision tree using the export_text function. The resulting tree displays the rules for classifying new instances based on their feature values.
Conclusion:
In conclusion, decision trees are powerful and widely used machine learning algorithms that can be used for both classification and regression problems. They are relatively easy to interpret, can handle both categorical and numerical data, and can handle missing values.
However, decision trees are sensitive to outliers, may overfit if not pruned properly, and can have stability issues due to small changes in the training data.
It is important to be aware of these assumptions, limitations, and challenges while working with decision trees, and to take appropriate measures to address them. With proper preprocessing, pruning, and validation, decision trees can be a valuable tool in data analysis and predictive modeling.

